
Deep learning là một phạm trù của công nghệ machine learning liên quan đến các thuật toán dựa trên cấu trúc và chức năng của não bộ và được gọi là mạng nơ-ron nhân tạo.
Nếu bạn khởi đầu ngay vào lĩnh vực deep learning hoặc đã từng có kinh nghiệm về mạng nơ-ron trước đây, có lẽ bạn sẽ thấy bối rối chẳng hạn như nhiều người làm việc trong lĩnh vực này cho biết họ cũng cảm thấy rối rắm khi học và áp dụng mạng nơ-ron vào những năm 1990 và đầu những năm 2000.
Những người đi đầu và các chuyên gia về lĩnh vực này đã đưa ra lời giải thích rõ về deep learning cùng với những đặc điểm và quan điểm đa dạng cũng đã làm sáng tỏ về công nghệ deep learning.
Trong bài viết này, các chuyên gia và người đi đầu về lĩnh vực này sẽ chia sẽ những hiểu biết của họ về công nghệ deep learning.
Hãy cùng lamphimquangcao.tv xem qua nhé!

Deep Learning là một Mạng Nơ-ron To lớn
Andrew Ng đến từ công ty Coursera và là Giám đốc khoa học tại Viện nghiên cứu Baidu đã chính thức thành lập ra dự án Google Brain mà qua đó đã áp dụng nhiều công nghệ deep learning vào một lượng lớn dịch vụ của Google.
Ông đã có nhiều bài viết và phát biểu về deep learning cũng như phải bắt đầu nó như thế nào.
Ở những bài phát biểu đầu tiên về deep learning, Andrew mô tả deep learning theo ngữ cảnh của một mạng lưới nơ-ron nhân tạo truyền thống. Trong bài phát biểu năm 2013 với tiêu đề “Deep Learning, Self-Taught Learning and Unsupervised Feature Learning”, ông đã mô tả deep learning như là:
“Sử dụng sự mô phỏng của não bộ để:
- Làm cho việc học các thuật toán trở nên tốt và dễ dàng hơn cho việc sử dụng
- Tạo ta những tiến bộ mang tính cách mạng trong công nghệ machine learning và AI.
Tôi tin đây là điểm sáng giá nhất trong quy trình hướng đến công nghệ AI thực sự của mình.”
Sau đó ý kiến của ông đưa ra trở nên sắc bén hơn.
Cốt lõi của deep learning theo ông Andrew là chúng ta hiện tại đã có nhiều máy tính đủ nhanh cùng với lượng dữ liệu vừa đủ để train các mạng lưới neural lớn. Khi thảo luận vì sao đây là thời điểm deep learning bùng bổ tại ExtractConf 2015 trong buổi trò chuyện mang tựa đề “What data scientists should know about deep learning“, ông Andrew bình luận:
“Những mạng lưới nơ-ron rất lớn mà chúng ta hiện tại đã có đủ lượng dữ liệu khổng lồ khi truy cập vào”
Ông cũng đề cập điểm mấu chốt quan trọng của công nghệ ngày đó là về quy mô. Có nghĩa là khi ta xây dựng một mạng lưới neural lớn và nạp càng nhiều dữ liệu vào thì hệ thống sẽ vận hành càng nhanh. Đây là điểm khác biệt với các công nghệ machine learning khác khi nó chỉ đạt được tốc độc vận hành ổn định.
“Nói đến các thể loại thuật toán machine learning thế hệ cũ…. Việc vận hành chỉ đạt mức ổn định…. Deep learning…. là một dạng thuật toán cao cấp… nó có thể biến đổi được…. việc vận hành sẽ càng nhanh khi bạn nạp càng nhiều dữ liệu vào nó.”
Ông cũng cung cấp một hình minh họa thú vị vào slide của mình

Cuối cùng ông nói rõ về những lợi ích từ deep learning mà chúng ta thấy từ thực tế đều đến từ việc học có sự giám sát. Trong cuộc nói chuyện tại ExtractConf 2015, ông phát biểu:
“Hầu hết các giá trị ngày nay của deep learning đều trải qua việc “học” có giám sát hoặc “học” từ dữ liệu có sẵn.”
Trước đó tại buổi trò chuyện tại trường đại học Stanford với chủ để “Deep Learning” vào năm 2014 ông cũng đã đưa ra phát biểu tương tự:
“Một lý do mà deep learning bùng nổ dữ dội đó là bởi sự tuyệt vời của nó ở việc “học” có giám sát”
Ông Andrew thường đề cập rằng chúng ta nên và sẽ nhận ra được nhiều lợi ích đến từ việc không thể giám sát được việc “học” ở các lĩnh vực nhằm giải quyết với lượng lớn dữ liệu không có sẵn
Jeff Dean được ví như một Phù thủy và Google Senior Fellow trong Systems and Infrastructure Group và đã tham gia và có lẽ có một phần trách nhiệm trong việc nhân rộng và phát triển deep learning tại Google. Jeff cũng đã đóng góp thực hiện dự án Google Brain và sự phát triển của phần mềm deep learning quy mô lớn là DisBelief và sau đó là TensorFlow.
Ở bài phát biểu năm 2016 với tựa đề “Deep Learning for Building Intelligent Computer Systems”, ông cũng đã đưa ra bình luận tương tự rằng deep learning thực ra là những mạng lưới nơ-ron lớn.
“Khi nghe đến thuật ngữ deep learning, chúng ta chỉ nghĩ đến một lưới deep nơ-ron lớn. Deep đề cập đến số lượng layer điển hình và do đó thuật ngữ này đã được áp dụng rộng rãi trên báo chí. Cá nhân tôi nghĩ nó là những mạng lưới deep nơ-ron nói chung. “
Ông đã nói vài lần nói đến chủ đề này và trong tập hợp các slide đã được sửa đổi cho phù hợp với cùng một chủ đề, ông lại làm nổi bật lên khả năng nở rộng của mạng lưới nơ-ron mà qua đó sẽ cho ra kết quả tốt hơn với nhiều dữ liệu và mô hình lớn hơn nhưng đòi hỏi việc train nó sẽ cần tính toán nhiều hơn.

Deep Learning là Việc học Tính Năng Phân cấp
Cùng với khả năng mở rộng, những lợi ích đáng chú ý từ các mô hình deep learning đó là khả năng nó thực hiện việc trích xuất các tính năng tự động từ dữ liệu thô. Do nó người ta gọi nó là feature learning.
Yoshua Bengio là một người dẫn đầu khác ở lĩnh vực deep learning và trước đây ông từng hứng thú đến tính năng học tự động mà mạng lưới neural lớn có thể đạt được.
Ông mô tả deep learning dưới dạng thuật ngữ thuật toán và đó là khả năng khám phá và học hỏi các tính năng tốt qua việc sử dụng feature learning. Trong bài báo năm 2012 với tiêu đề “Deep Learning of Representations for Unsupervised and Transfer Learning”, ông phát biểu:
“Thuật toán deep learning luôn tìm cách khai thác những cấu trúc mới lạ trong input distribution nhằm khám phá ra các representation hấp dẫn và thường ở nhiều cấp độ với các tính năng học cấp cao được xác định dưới dạng các tính năng cấp thấp hơn”
Một quan điểm phức tạp về deep learning liên quan đến vấn đề này đã được ông đề cập vào báo cáo kỹ thuật của mình vào năm 2009 với tiêu đề “Learning deep architectures for AI”. Qua đó ông đã nhấn mạnh đến tầm quan trong của hệ thống phân cấp trong feature learning.
“Các phương pháp deep learning trong hệ thống phân cấp các thuộc tính với các thuộc tính cấp cao của hệ thống phân cấp đều do sự tổng hợp của các thuộc tính cấp thấp hơn tạo thành. Các tính năng học tự động với nhiều cấp độ trừu tượng cho phép hệ thống có thể học các hàm phức hợp đầu vào và đầu ra trực tiếp từ dữ liệu mà không hoàn toàn phụ thuộc vào các tính năng cho con người tạo ra.”
Trong cuốn sách sắp xuất bản “Deep Learning” đồng tác giả với Ian Goodfellow và Aaron Courville, họ định nghĩa deep learning dưới góc độ kiến trúc của các hình mẫu:
“Hệ thống phân cấp của concept này cho phép máy tính có thể học được nhiều concept phức tạp hơn bằng cách bức phá ra khỏi các concept đơn giản khác. Nếu chúng ta đã vẽ ra một biểu đồ cho thấy được các concept này được xây dựng theo mô hình xếp chồng lên nhau như thế nào thì biểu đồ đó phải sâu, phải nhiều lớp. Vì lí do đó mà chúng tôi gọi bước tiến này chính là AI deep learning. “
Đây thật là một quyển sách hay và dường như sẽ trở thành sách tham khảo cuối cùng cho các lĩnh vực vào một lúc nào đó. Cuốn sách vẫn tiếp tục mô tả mô hình perceptron đa lớp này như là một thuật toán được áp dụng trong các lĩnh vực về deep learning và mang đến giả thuyết rằng deep learning đã được gộp vào mạng lưới nơ-ron nhân tạo.
“Ví dụ sáng giá của một mô hình deep learning là mạng lướp deep feedforward hoặc mô hình perceptron đa lớp (MLP).”
Peter Norvig là Giám đốc Nghiên cứu tại Google đồng thời cũng là tác giả của quyển sách nổi tiếng “Artificial Intelligence: A Modern Approach”.
Trong cuộc trò chuyện vào năm 2016 với tên gọi “Deep Learning and Understandability versus Software Engineering and Verification”, ông định nghĩa deep learning theo cách tương tự như Yoshua qua việc chú trọng vào sức mạnh của sự trù tượng được cho phép bằng cách sử dụng một cấu trúc mạng deep.
Tùy theo các loại learning mà representation bạn tạo ra sẽ có nhiều mức trừu tượng khác nhau hơn là các lớp input và output trực tiếp.
Tại sao lại gọi nó là “Deep Learning”?
Tại sao không chỉ là “Mạng lưới nơ-ron nhân tạo”?
Geoffrey Hinton là một người tiên phong trong lĩnh vực về mạng lưới nơ-ron nhân tạo và đồng xuất bản bài báo đầu tiên viết về thuật toán backpropagation cho việc train các mạng lưới perceptron đa lớp.
Đầu tiên ông đã có lời giới thiệu về từ “deep” nhằm mô tả sự phát triển của mạng lưới nơ-ron nhân tạo lớn.
Ông cũng đã đồng chắp bút cho bài báo năm 2006 với tiêu đề “A Fast Learning Algorithm for Deep Belief Nets” mà trong đó đã mô tả một bước tiến đến việc train “deep” (như trong mạng lưới nhiều lớp) của các máy Restricted Boltzmann (RBMs).
“Bằng việc sử dụng các biện pháp bổ sung, chúng tôi đã tìm ra được một thuật toán nhanh có thể học sâu, định hướng mạng lưới belief mỗi lớp một lần với điều kiện là hai lớp trên cùng phải tạo được một bộ nhớ kết hợp vô hướng.”
Bài báo này cùng với những bài viết liên quan của Geoff với tiêu đề “Deep Boltzmann Machines” mà qua đó mạng lưới deep vô hướng luôn được cộng đồng đón nhận nồng nhiệt vì đó là những ví dụ thành công về việc training mạng greedy layerwise và cho phép nhiều lớp hơn trong mạng lưới feedforward.
Trong một bài báo đồng tác giả ở mục Science có tiêu đề “Reducing the Dimensionality of Data with Neural Networks”, họ đều đưa ra các định nghĩa tương tự về “deep” nhằm mô tả bước tiến của họ đến việc phát triển mạng lưới nhiều lớp hơn.
“Chúng tôi mô tả một cách hữu hiệu về thiết lập cho phép mạng lưới deep autoencoder có thể học các đoạn mã chiều thấp vận hành hữu hiệu hơn việc phân tích các thành phần chính như là một công cụ nhằm đơn giản hóa dữ liệu. “
Ở bài báo tương tự, họ đã đưa ra một bình luận thú vị ăn khớp với bình luận của Andrew Ng trong sự gia tăng gần đây về sức mạnh và khả năng truy cập vào các bộ dữ liệu lớn mà qua đó đã khai thác được khả năng chưa sử dụng của mạng nơ-ron khi được sử dụng ở quy mô lớn hơn.
“Rõ ràng kể từ những năm 1980, các backpropagation qua deep autoencoder sẽ rất hiệu quả đối với việc giảm chiều không tuyến tính, miễn là các máy tính đủ nhanh, các bộ dữ liệu đủ lớn và trọng lượng ban đầu vừa đủ. Cả ba điều kiện này hiện nay đều đã được đáp ứng.”
Tại buổi nói chuyện tại Hội hoàng gia London năm 2016 xoay quanh “Deep Learning“, Geoff nói rằng Deep Belief Networks chính là khởi đầu của Deep learning vào năm 2006 và ứng dụng thành công đầu tiên về làn sóng công nghệ deep learning này là công nghệ nhận diện giọng nói trong năm 2009 với tiêu đề “Acoustic Modeling using Deep Belief Networks“ và qua đó đã đạt được các thành quả về công nghệ deep learning tân tiến nhất.
Đây quả thực là kết quả làm cho việc nhận diện giọng nói và mạng lưới nơ-ron được chú ý đến. Việc sử dụng “deep” như là sự khác biệt về các kỹ thuật mạng nơ-ron trước đây có thể dẫn đến tên gọi sẽ thay đổi.
Việc mô tả deep learning trong cuộc trò chuyện tại Hội hoàng gia London đều xoay quanh về backpropagation. Điều thú vị là ông đưa ra 4 lý do vì sao mà backpropagation không bùng nổ vào những năm 1990. Hai quan điểm đầu tiên đều ứng với quan điểm của Andrew Ng ở trên về bộ dữ liệu thì quá nhỏ còn máy tính thì quá chậm.
 Slide by Geoff Hinton, all rights reserved.
Slide by Geoff Hinton, all rights reserved.
Deep Learning như khả năng mở rộng việc học qua tên miền
Deep learning vượt trội ở vấn đề tên miền khi mà input và output tương tự nhau. Có nghĩa là chúng không phải là số lượng nhỏ trong định dạng bảng mà thay vào đó là dữ liệu pixel của hình ảnh, dữ liệu văn bản của tài liệu hay dữ liệu audio của tệp tin.
Yann LeCun hiện đang là giám đốc tại Facebook Research và là cha đẻ của kiến trúc mạng vượt trội về mặt nhận diện vật thể trong dữ liệu hình ảnh có tên gọi là Convolutional Neural Network (CNN). Kỹ thuật này đã cho thấy được thành công vượt trội vì giống như mạng nơ-ron perceptron feedforward đa lớp, kỹ thuật này cũng mở rộng dữ liệu, kích cỡ mô hình và có thể được training với backpropagation.
Điều này làm sai lệch định nghĩa của ông về deep learning như sự phát triển về kiến trúc mạng CNN vượt trội ở khả năng nhận diện vật thể trong hình ảnh.
Trong bài phát biểu tại Lawrence Livermore National Laboratory năm 2016 với tên gọi “Accelerating Understanding: Deep Learning, Intelligent Applications, and GPUs”, ông mô tả deep learning nói chung như là việc học representation theo thứ bật và định nghĩa nó là một bước tiến mở rộng trong việc xây dựng hệ thống nhận diện vật thể.
“Deep learning như là một ống dẫn của các mô-đun có thể training được…. deep là vì nó có nhiều bước trong quy trình nhận diện vật thể và tất cả các bước này là một phần của việc training”
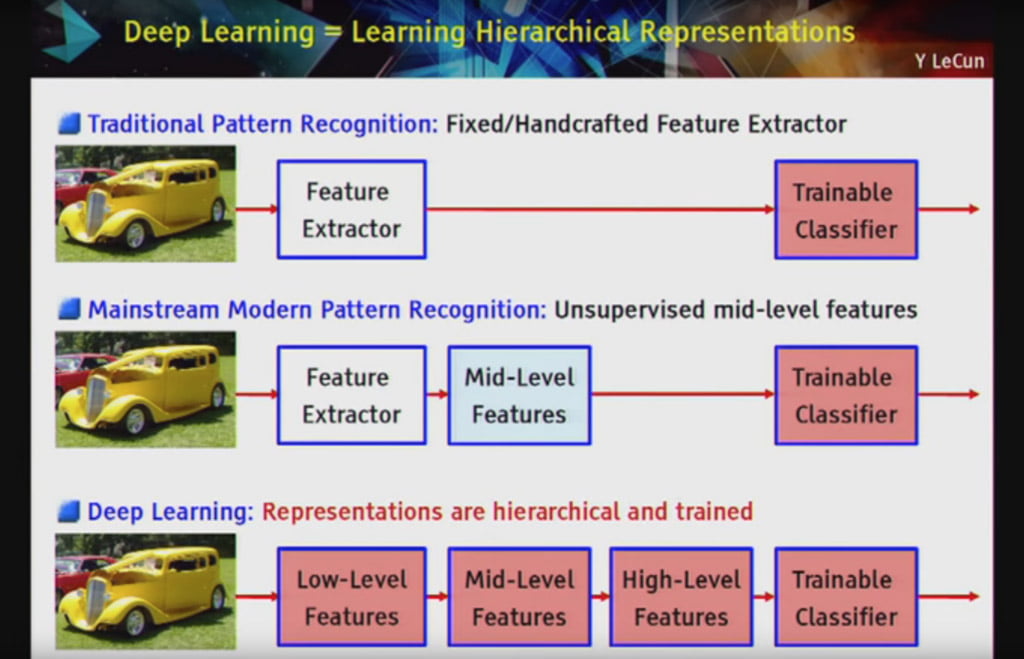 Deep Learning = Learning Hierarchical Representations
Deep Learning = Learning Hierarchical Representations
Slide by Yann LeCun, all rights reserved.
Jurgen Schmidhuber được ví như là cha đẻ của một thuật toán phổ biến tương tự như MLP và CNN mở rộng kích cỡ hình mẫu hay dữ liệu và có thể training với backpropagation nhưng thay vào đó nó được thiết để để học các chuỗi dữ liệu và được gọi là Long Short-Term Memory Network (LSTM), một dạng mạng nơ-ron lặp lại.
Có lẽ chúng ta cũng đã biết những khúc mắc xoay quanh thuật ngữ “deep learning”. Trong bài báo năm 2014 có tựa đề “Deep Learning in Neural Networks: An Overview”, Jurgen Schmidhuber đã bình luận về vấn đề hóa trong việc đặc trên và những khác biệt giữa học deep và shallow. Ông cũng đã mô tả hấp dẫn từ depth theo tính phức tạp của vấn đề hơn là hình mẫu sử dụng nhằm giải quyết những vấn đề đó.
Demis Hassabis là người thành lập nên công ty DeepMind nhưng sau đó đã bị Google thâu tóm. DeepMind đã có một cú hích trong việc kết hợp giữa các kỹ thuật deep learning với reinforcement learning nhằm xử lý những vấn đề học tập có tính phức tạp như việc chơi game được minh họa trong trò chơi Atari và Go trong Alpha Go.
Để giữ lại tên gọi, họ gọi kỹ thuật mớ của mình là Deep Q-Network qua việc kết hợp Deep Learning và Q-Learning. Họ còn đặt tên cho trường nghiên cứu rộng hơn của mình là “Deep Reinforcement Learning”.
Trong bài báo “Human-level control through deep reinforcement learning” năm 2015, Demis Hassabis đã giải thích về vai trò quan trọng của mạng nơ-ron deep đối với thành công của công ty và làm nổi bật lên sự cần thiết của sự trừu tượng phân cấp.
Để đạt được thành công này, chúng tôi đã phát triển một nhân tố mới có tên gọi là Deep Q-Network (DQN) có khả năng kết hợp reinforcement learning với một dạng của mạng nơ-ron nhân tạo được biết đến như là mạng nơ-ron deep. Đáng chú ý là những lợi thế gần đây về mạng nơ-ron sâu mà trong đó nhiều lớp của các node được sử dụng nhằm dựng lên nhiều representation trừu tượng của dữ liệu và điều đó đã khả thi khi mạng nơ-ron nhân tạo có thể học được các concept như là danh mục vật thể trực tiếp từ dữ liệu thô.
Cuối cùng trong bài viết mà Yann LeCun, Yoshua Bengio và Geoffrey Hinton xuất bản trong tờ Nature có tiêu đề “Deep Learning“ đã mở ra một định nghĩa mới về deep learning bằng việc nêu bật lên phương pháp tiếp cận đa lớp.
“Deep learning cho phép các mô hình tính toán được tạo thành từ nhiều lớp xử lý có thể học các representation của dữ liệu với nhiều cấp độ khác nhau của sự trừu tượng.”
Sau đó phương pháp tiếp cận đa lớp được miêu tả dưới hình thức representation learning và trừu tượng.
“Các giải pháp Deep-learning là các giải pháp về representation-learning với nhiều cấp độ khác nhau của representation thu được bằng cách sắp xếp các mô-đun đơn giản nhưng phi tuyến tính mà qua đó mỗi mô-đun này có thể chuyển đổi các representation từ cấp độ đầu tiên (khởi đầu với input thô) sang representation cao hơn và trừu tượng hơn một chút. [….] Khía cạnh chủ chốt của deep learning là các lớp tính năng thường không do các kỹ sư là con người thiết kế mà nó học từ dữ liệu bằng cách sử dụng một thủ tục học tập chung.”
Đây quả thực là định nghĩa chung và đầy đủ, và hoàn toàn có thể dễ dàng mô tả cho hầu hết các thuật toán về mạng nơ-ron nhân tạo.
Tóm lại
Trong bài viết này, bạn đã nhận ra được deep learning chỉ là mạng lưới nơ-ron rất lớn với nhiều dữ liệu và do đó đòi hỏi máy tính vận hành cũng lớn theo.
Dù những bước đầu tiên do Hinton và các cộng sự cùng xuất bản chú trọng vào việc training các greedy layerwise và các phương pháp không được giám sát như audoencoders nhưng công nghệ deep learning hiện đại nhất ngày nay chú trọng vào việc training các mô hình mạng nơ-ron deep (nhiều lớp) bằng cách áp dụng các thuật toán backpropagation. Những kỹ thuật phổ biến đó là
- Mạng Perceptron Đa Lớp
- Mạng Nơ-ron Xoắn
- Long Short-Term Memory Recurrent Neural Networks.




