Trong AI generative, mô hình phổ biến để tạo hình ảnh sử dụng latent space làm không gian biểu diễn nhiễu (noise). Từ input là văn bản prompt (và có thể kèm hình ảnh) được encode thành latent space, model thực hiện quá trình denoising từng bước để chuyển không gian này thành hình ảnh có cấu trúc mà con người có thể hiểu (visual). Quá trình inference chạy trên GPU để biến prompt và dữ liệu đầu vào thành output cuối cùng, và sẽ tiêu tốn tài nguyên GPU hoặc credit khi sử dụng các dịch vụ Cloud.
Sau khi có hình ảnh là 1 frame, để làm video thì ta lại tiếp tục làm như vậy cho nhiều frame hơn thành một chuỗi frame thì gọi là clip -> clip chuyển động. (Hay còn gọi là SHOT)

Từ clip qua clip thì đó chính là một sequence (một trường đoạn nội dung gồm nhiều clip). Một sequence này có thể chứa nhiều clip khác về bố cục, camera, vật thể hiển thị, thành phần, màu sắc, chuyển động của nhân vật, vật liệu. Mọi thứ đều chắc chắn không liên tục qua mỗi frame, và cái việc nhất quán khi generative đó là phải từ frame sang tới các sequence này.
Các sequence (trường đoạn) nối với nhau thì ta có một phân đoạn có nội dung (segmentation), kể một câu truyện, gửi một thông điệp, giữa các clip gọi là cut nếu là đang biên tập video. Đây là tổng hòa mọi thứ mà một nền tảng AI generative phải làm cho một nội dung AI generative theo qui trình tuyến tính.

Đây là cái khó khăn mà mọi AI prompter hiện nay đang cố thực hiện bằng nhiều cách, nhiều AI model với mục tiêu làm sao kiểm soát tốt nhất, sâu nhất, thay đổi được nhiều (iteration) mà tốn ít chi phí nhất. Có thể nói KPI của một AI prompter nếu có sẽ chính là “số lần generate dưới x lần” “tối thiểu token cho n lần iteration”, vì mỗi lần generate là tốn chi phí, tốn thời gian. Nếu dùng cloud thì tốn phí, dùng Comfy UI chạy nội bộ thì tốn thời gian.
Nhưng AI generative nói chung hiện nay đều không thể lưu như lưu game, từ frame 1 qua frame 2 và frame 3 là các frame riêng lẽ, nó không hề biết làm sao để nhớ các bước đã trãi qua, việc nó thấy frame 1 không có nghĩa là nó sẽ nối cái “motion flow” chuyển động đó tạo ra frame 3, nên còn được biết gọi là “stateless” (trí khôn ta đâu). Giống kiểu lưu game, nó không có cái này.
Nếu nó làm được kiểu dồn tích đó, chắc chắn nó sẽ làm được AI Physic Simulation là thứ mà hiện tại đang rất là độc quyền riêng của thế giới CG dynamic simulation (tìm hiểu thêm về dynamic simulation với Houdini thay vì AI generative), data flow liên tục, dồn tích mới có kết quả. Kết quả simulation trong video.
Trong thế giới kiến tạo nội dung hiện tại, một mô hình AI generative lý tưởng hóa thường được mong đợi là có thể kiểm soát được mọi thứ về sáng tạo, tất tần tật từng chi tiết, và cả giàn dựng nó. Kiểu như vậy như trong video dưới đây. Dĩ nhiên về mặt sử dụng, nhắm vào phần đông nhà sáng tạo không phải là người làm kỹ thuật, nên tốt nhất phải ít phức tạp hơn CG và tiện lợi hơn nhưng vẫn kiểm soát được đó là đích đến của mọi giải pháp hiện nay. Cả đạo diễn James Cameron cũng muốn vậy.
Comfy-UI là một cái app hòng giải quyết một phần cái này theo dạng modular, các bước sẽ được ghi nhận lại qua các operator và giữ nhất quán tối ưu nhất kết quả theo pipeline đã thiết lập. (Comfy UI là gì, đọc ở đây để biết đến cái app tạo và biên tập hình ảnh, video AI generative trên máy cục bộ)
Không riêng gì Comfy UI, các cloud base hiện nay đều cố làm theo phương cách này, giúp cho quá trình sáng tạo được kiểm soát chặt chẽ nhất, đặc biệt là áp dụng vào thương mại. Tập trung chính là giữ cho tính nhất quán cả kết quả trả về và ý tưởng chủ đạo của AI luôn nhất quán khi generate.
Với một frame hình thì dễ, nhưng với video luôn phức tạp, phương án trước đây của nhiều AI generative là có frame, rồi từ frame sẽ sinh ra frame mới, hoặc ghi nhận các tiểu tiết làm input rồi lại xử lý ra frame mới, kết quả chớp nháy múa lụa là vẫn xảy ra.
Đó cũng là lý do mà các technical artist, pipeline artist và các artist trong các workflow truyền thống không qua lo lắng về việc video generate như Seedance. Đơn giản là vì đằng nào cũng cần phải áp dụng qui trình làm việc tiêu chuẩn, phải chạy qua các mô hình kiểm soát sáng tạo có thể thủ công được, AI chẳng qua là một lớp nữa lên các qui trình kiến tạo nội dung mà thôi. Đọc thêm bài viết này về về AI generative bước vào VFX & Animation
Kể từ khi đó, rất nhiều nghiên cứu ứng dụng đã lao vào để tạo ra các phương thức vô tiền khoán hậu trong thời gian vô cùng ngắn, đặc biệt là Trung Quốc cạnh tranh với nhóm các nước phương Tây. Và đặc biệt nữa là dòng chảy của dòng tiền đầu tư vào AI là vô hạn nên các nghiên cứu ứng dụng lại càng làm các nhà khoa học trẻ già khắp nơi xung phong giương cờ làm lụng.
Trong đó có cái này -> Dance-Your-Latents, một khung làm việc (framework) nhằm giải quyết vấn đề mất ổn định hình ảnh (flickering, ghosting) khi tạo video nhảy từ AI. Bằng cách hướng dẫn các biến tiềm ẩn (latents) chuyển động đồng nhất theo dòng chảy động tác (motion flow), paper giúp tạo ra những video nhân vật nhảy mượt mà và nhất quán hơn so với các phương pháp tạo từng khung hình rời rạc trước đây.
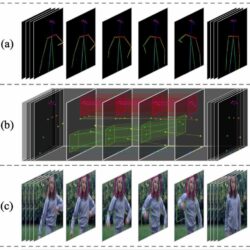
Cơ chế Spatial-Temporal Subspace Attention (STSA) | Chia Để Trị
Thay vì tính toán sự chú ý (attention) trên toàn bộ không gian (latent space) video gây tốn kém tài nguyên và dễ làm nhiễu loạn chi tiết, các tác giả chia không gian toàn cục thành các không gian con (subspaces) nhỏ hơn. Việc này dựa trên quan sát rằng phần lớn bối cảnh và các bộ phận cơ thể thường chỉ chuyển động trong một phạm vi hẹp nhất định. Bằng cách áp dụng cơ chế chú ý trong các không gian con này, mô hình ép mỗi điểm ảnh phải tập trung vào các khu vực lân cận xung quanh nó thay vì phân tán sự chú ý ra quá xa, từ đó giảm thiểu hiện tượng bóng ma và nhiễu hình. Để đảm bảo tính thống nhất trên toàn bộ video, cơ chế Subspace Shift được sử dụng để luân chuyển và kết nối thông tin giữa các không gian con khác nhau, tạo nên một sự nhất quán tổng thể xuyên suốt các khung hình.
Vấn đề cốt lõi: Vì sao video AI bị “vỡ consistency”
Trong các hệ diffusion ban đầu, video được tạo bằng cách mở rộng từ bài toán generate ảnh: mỗi frame hình ảnh được tạo riêng lẻ trong latent space rồi ghép lại thành video. Cách này đơn giản nhưng có vấn đề lớn vì mỗi frame là một lần lấy mẫu độc lập (đã giải thích ở đầu bài), nên không có gì đảm bảo rằng nhân vật, chi tiết bề mặt hay cấu trúc hình học sẽ ổn định theo thời gian. Vì vậy dễ xuất hiện các lỗi như hình bị nhấp nháy (flickering), chồng hình (ghosting), hoặc khuôn mặt thay đổi bất thường giữa các frame hình ảnh.
Về bản chất, đây là vấn đề thiếu spatiotemporal consistency: mô hình không coi video là một thực thể liên tục theo không gian và thời gian, mà chỉ xử lý nó như một tập hợp các hình ảnh rời rạc. Nên mới phải cần tới các hướng tiếp cận tạo ra tính nhất quán trong AI video/image generative.
Paper “Dance Your Latents”: Một hướng tiếp cận học thuật điển hình
Paper Dance Your Latents (arXiv:2310.14780) là một ví dụ rất rõ của hướng học thuật.
Trong mô hình này, thay vì để mọi phần của video “nhìn” và tương tác với tất cả các phần khác (attention toàn cục), người ta chia không gian và thời gian thành các vùng nhỏ hơn gọi là subspace, và mỗi phần chỉ tương tác với các phần gần nó.
Attention là cơ chế giúp mô hình chọn ra những phần quan trọng nhất trong dữ liệu để tập trung xử lý khi tạo ra kết quả.
Điều này phù hợp với thực tế vì trong video, hầu hết các vật thể chỉ di chuyển trong phạm vi nhỏ giữa các khung hình. Ngoài ra, họ sử dụng motion flow guided alignment, nghĩa là dùng thông tin về tư thế (pose) để hướng dẫn cách các đặc trưng trong latent space di chuyển theo thời gian, thay vì để mô hình tự suy ra chuyển động.
Nhờ vậy, chuyển động trở nên có kiểm soát và ổn định hơn, tránh tình trạng attention bị phân tán và làm mất cấu trúc hình ảnh. Tuy nhiên, phương pháp này được thiết kế cho bài toán cụ thể như tạo video chuyển động theo pose (ví dụ như nhảy nhót trên Douyin, Tiktok), nên phụ thuộc vào dữ liệu pose và không áp dụng chung cho mọi loại video.
Seedance: Một bước tiến khác — không còn “frame thinking”
Theo paper (Seedance 1.0, arXiv:2506.09113), cách tiếp cận đã thay đổi hoàn toàn.
Seedance không chỉ thay đổi cách dùng attention mà còn thay đổi cấu trúc của mô hình. Họ tách riêng hai phần: spatial layer để xử lý nội dung trong từng frame, và temporal layer để xử lý mối quan hệ giữa các frame theo thời gian. Nhờ vậy, mô hình không bị trộn lẫn giữa thông tin hình ảnh và chuyển động, giúp kết quả rõ ràng và ổn định hơn. Ngoài ra, họ sử dụng temporally-causal VAE, nghĩa là dữ liệu trong latent space đã chứa thông tin về thời gian ngay từ đầu, thay vì phải sửa lỗi nhất quán sau khi tạo video. Một điểm quan trọng khác là họ huấn luyện với multi-shot và dense captioning, tức là mô hình học không chỉ chuyển động mà còn cách các cảnh liên kết với nhau về mặt nội dung. Điều này giúp video giữ được sự nhất quán không chỉ giữa các frame mà còn giữa nhiều đoạn khác nhau.
VAE (Variational Autoencoder) là một mô hình gồm hai phần: encoder biến dữ liệu đầu vào (như hình ảnh) thành một biểu diễn nén gọi là latent, và decoder dùng latent đó để tái tạo lại dữ liệu. Điểm khác biệt của VAE là nó không mã hóa thành một điểm cố định, mà thành một phân phối xác suất (thường là mean và variance), giúp mô hình có thể sinh ra nhiều kết quả khác nhau một cách mượt mà.
Temporally-causal VAE là phiên bản mở rộng cho dữ liệu theo thời gian (như video), trong đó việc mã hóa tuân theo thứ tự thời gian: mỗi thời điểm chỉ sử dụng thông tin từ hiện tại và quá khứ, không dùng thông tin từ tương lai. Nhờ vậy, latent representation giữ được tính liên tục và nhất quán theo thời gian, giúp mô hình tạo ra video ổn định hơn.
Tóm lại, Seedance không “propagate frame”, mà generate toàn bộ video như một cấu trúc thống nhất trong latent space.
So sánh bản chất các hướng tiếp cận
Dance Your Latents giải bài toán bằng cách giới hạn phạm vi attention và sử dụng motion flow để căn chỉnh các đặc trưng trong latent space, giúp giữ được sự nhất quán cục bộ giữa các phần gần nhau trong video.
Các hệ như Runway và Kling tiếp tục cải tiến bằng cách bổ sung temporal modeling vào pipeline diffusion, tức là giúp mô hình hiểu mối quan hệ theo thời gian, nhưng vẫn còn phụ thuộc vào cách xử lý từng frame riêng lẻ.
Seedance đi xa hơn bằng cách thiết kế lại toàn bộ kiến trúc theo hướng spatiotemporal-first, nơi video được biểu diễn như một tensor thống nhất có cả không gian và thời gian, thay vì chỉ là chuỗi các frame tách rời.
Consistency không phải là “giữ giống”, mà là “giữ cấu trúc”
Một hiểu lầm phổ biến là (tính nhất quán) consistency = giữ nguyên pixel hoặc appearance. Nhưng thực tế, consistency nằm ở:
- identity (face, object)
- geometry (cấu trúc)
- motion logic (chuyển động hợp lý)
- narrative continuity
Các model tốt không “copy frame trước”, mà duy trì trajectory trong latent space.
Consistency (tính nhất quán) không phải là việc giữ cho hình ảnh trông giống nhau qua các frame, mà là giữ cho cấu trúc và mối quan hệ giữa các phần của hình ảnh được ổn định theo thời gian. Điều này có nghĩa là vị trí, hình dạng, và cách các thành phần liên kết với nhau không bị thay đổi bất thường, ngay cả khi có chuyển động hoặc thay đổi góc nhìn.