ComfyUI là một công cụ AI dạng node-based dùng cho Stable Diffusion (hay nhiều model khác của AI generative), cho phép người dùng tạo và chỉnh sửa hình ảnh bằng cách kết nối các node thành workflow tùy chỉnh. Mỗi node đại diện cho một bước như load model, xử lý prompt hay tạo ảnh. Nhờ đó, người dùng có thể kiểm soát toàn bộ quá trình và linh hoạt thử nghiệm. ComfyUI hỗ trợ nhiều tính năng như text-to-image, inpainting, nâng cao chất lượng ảnh và kết hợp nhiều model khác nhau. Đây là một môi trường sáng tạo mạnh mẽ, phù hợp cho cả người mới bắt đầu lẫn người dùng chuyên sâu muốn xây dựng pipeline AI phức tạp.
Comfy-UI không phải là một công cụ, nó là một hệ thống, nền tảng chứa các node AI xử lý được load vào bởi người dùng.
Ngược lại, các công cụ mã nguồn mở như ComfyUI mang một triết lý hoàn toàn khác. Người dùng có thể tự do chỉnh sửa, mở rộng và thậm chí tái định nghĩa cách phần mềm hoạt động. Chính cộng đồng sẽ là lực đẩy cho innovation thay vì chỉ một công ty. Điều này mở ra khả năng sử dụng AI vượt xa mục đích ban đầu, từ sáng tạo nghệ thuật đến các pipeline kỹ thuật phức tạp. Tuy nhiên, sự tự do này đi kèm với yêu cầu cao hơn về kỹ năng và hiểu biết hệ thống.
Nếu chưa biết cách cài đặt Comfy-UI cho người mới bắt đầu tạo và biên tập hình ảnh với AI generative thì đây là một số liên kết:
- Cách sử dụng Comfy-Ui cho người mới, có 11 node cần biết để tiện thao tác
- Cách cài đặt chỉ trong 5 phút là có Comfy-UI dùng
- Mở rộng cài thêm các node trên internet với công cụ quản lý node
- Tutorial hướng dẫn cách tạo hình ảnh Comfy-UI để bán hàng thương mại điện tử
- Cách mà Seedance đã giữ tính nhất quán consistency cho video
Mục tiêu chính là để người dùng hoàn toàn kiểm soát được nội dung, qui trình và biến tấu cách làm việc phù hợp với phong cách riêng, không bị gượng ép theo một sản phẩm thương mại bất kỳ.
Trong vài năm gần đây, các công cụ AI như Adobe Firefly, DALL·E hay MidJourney đã trở nên phổ biến nhờ khả năng biến text thành hình ảnh. Tuy nhiên, điểm chung của các hệ thống này là chúng đều là closed-source – nghĩa là người dùng không thể truy cập, chỉnh sửa hay mở rộng code bên trong. Điều này khiến người dùng phụ thuộc hoàn toàn vào nhà phát triển về tính năng, giới hạn nội dung và hướng phát triển sản phẩm. Bạn chỉ có thể tạo hình ảnh trong phạm vi cho phép, ví dụ không vi phạm bản quyền hay nội dung nhạy cảm, và gần như không có khả năng tùy biến sâu.
Diffusion: Cách AI “Vẽ” Hình Ảnh
Khái niệm diffusion có thể hiểu đơn giản qua ví dụ mùi nước hoa lan tỏa trong phòng. Ban đầu, mùi tập trung ở một điểm, sau đó dần lan đều ra không gian. Trong AI, diffusion cũng là quá trình tương tự nhưng theo chiều ngược lại: bắt đầu từ nhiễu (noise) và dần “tái cấu trúc” thành hình ảnh có ý nghĩa.
Stable diffusion là phiên bản có kiểm soát của quá trình này. AI không lan tỏa ngẫu nhiên mà đi theo một “con đường xác suất” đã được học trước. Ví dụ, với prompt “quả táo đỏ trên bàn”, AI sẽ tạo ra các đặc điểm lớn trước như hình dạng quả táo, màu đỏ, sau đó dần bổ sung chi tiết như ánh sáng, bóng đổ, texture cho đến khi hoàn chỉnh.
Diffusion có thể hiểu như bắt đầu từ một “nùi hỗn loạn” gọi là noise trong latent space, một không gian dữ liệu trừu tượng hỗn loạn không rõ ràng. Từ đó, model sẽ từng bước khử nhiễu (denoise) để hình ảnh dần hiện ra. Quá trình này được dẫn dắt bởi text prompt, thông qua một cơ chế như CLIP để chuyển ngôn ngữ thành vector ý nghĩa. GPU không “hiểu” hình ảnh mà chỉ thực hiện các phép tính xác suất để điều chỉnh noise theo hướng phù hợp. Đây chính là cách các hệ như MidJourney hay Stable Diffusion tạo ra hình ảnh từ văn bản.
Ngoài text prompt thì còn tham chiếu được thêm hình ảnh đầu vào, là một trong các cách giữ cho Comfy UI tạo ra hình ảnh luôn “consistency” nhất quán chứ không bị lúc thì ok lúc thì không phải người tôi yêu.
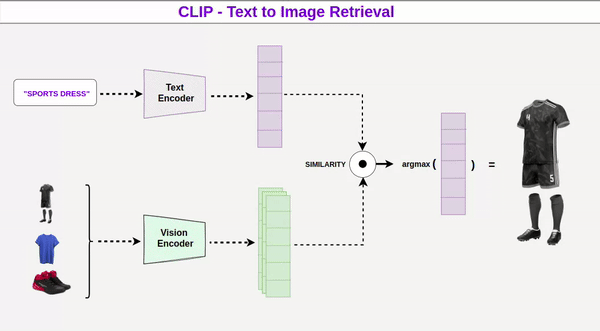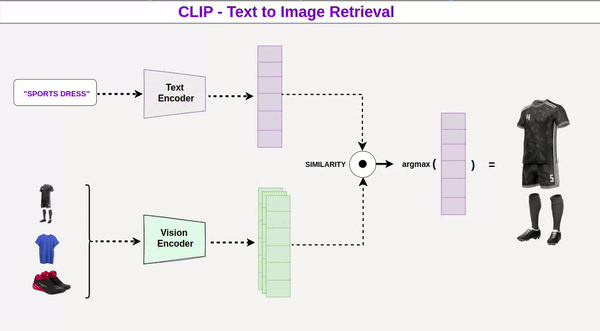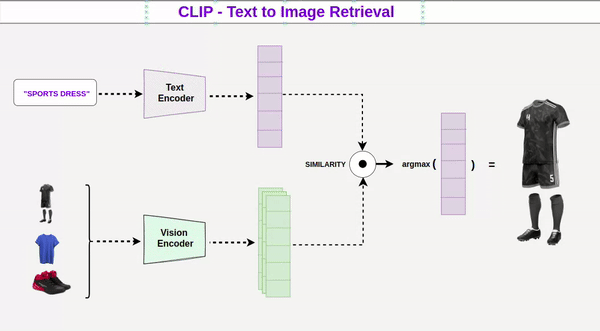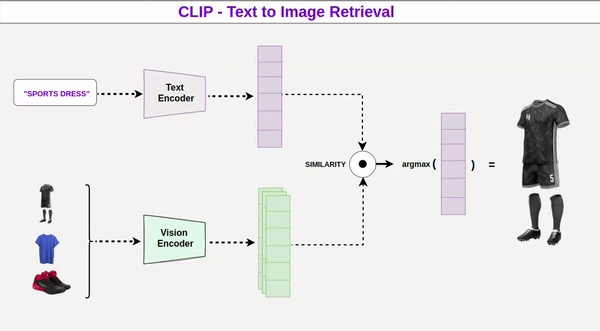
Vai Trò Của Model Được Huấn Luyện
Đằng sau toàn bộ quá trình là các model đã được huấn luyện trên hàng triệu hình ảnh và mô tả. Những model này hoạt động như một “rulebook”, giúp AI hiểu mối quan hệ giữa từ ngữ và hình ảnh. Khi nhận prompt, model sẽ dự đoán và xây dựng hình ảnh dựa trên xác suất – bắt đầu từ những yếu tố dễ nhận biết nhất, rồi dần thêm chi tiết phức tạp hơn.
Điểm quan trọng là: AI không “hiểu” theo cách con người hiểu, mà nó tái cấu trúc dựa trên pattern đã học. Điều này giải thích vì sao kết quả vừa có thể rất chính xác, vừa có thể đôi lúc sai lệch kỳ lạ.
Ý Nghĩa Lớn Hơn: Từ Tool Sang Infrastructure
Toàn bộ bài nói lên một chuyển dịch quan trọng: AI không còn chỉ là một công cụ tạo ảnh, mà đang trở thành hạ tầng sáng tạo (creative infrastructure). Closed-source tools giúp bạn tạo nhanh, nhưng bị giới hạn. Open-source như ComfyUI cho phép bạn xây dựng pipeline riêng, nhưng đòi hỏi tư duy hệ thống.
Trong bối cảnh hiện tại, sự khác biệt giữa người dùng không còn nằm ở việc “biết dùng tool”, mà là hiểu cách AI hoạt động và thiết kế workflow phù hợp với mục tiêu của mình. Đây chính là bước chuyển từ người dùng sang người xây dựng hệ thống sáng tạo bằng AI.